
AI 공부 저장소
[파이썬 머신러닝 완벽가이드] Chap01-2. pandas 라이브러리 2 본문
[파이썬 머신러닝 완벽가이드] Chap01-2. pandas 라이브러리 2
aiclaudev 2021. 12. 31. 22:21
- 본 글은 파이썬 머신러닝 완벽 가이드 (권철민 지음)을 공부하며 내용을 추가한 정리글입니다. 개인 공부를 위해 만들었으며, 만약 문제가 발생할 시 글을 비공개로 전환함을 알립니다.
[1] DataFrame에서 새로운 Column을 추가해보자!
import pandas as pd
titanic_df = pd.read_csv("C:/Users/82102/Desktop/sw/PythonMLGuide/pandas/titanic_train.csv")
titanic_df.head()
먼저 기존의 DataFrame을 확인해봅시다. PassangerId부터, Embarked라는 Column까지 있네요! 이제 이 DataFrame에 새로운 Column을 추가해봅시다.
titanic_df['Age_0'] = 0
titanic_df['Age_by_10'] = titanic_df['Age'] * 10
titanic_df['Family_No'] = titanic_df['SibSp'] + titanic_df['Parch'] + 1
titanic_df.head()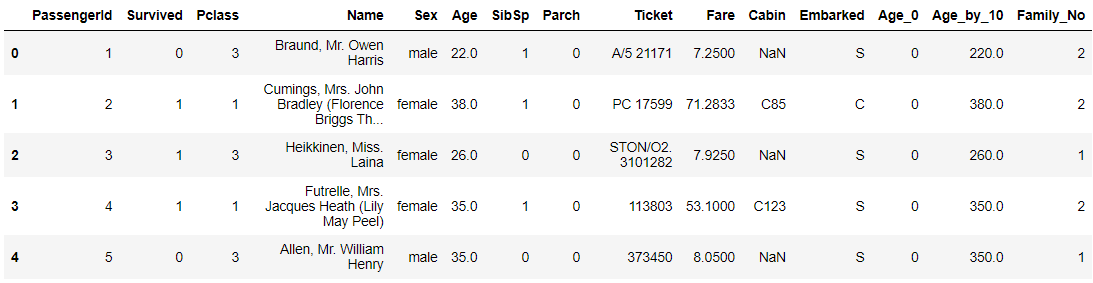
위 DataFrame에서 볼 수 있듯이, 저는 Age_0, Age_by_10, Family_No이라는 3개의 Column을 세롭게 추가하였습니다!
1) Age_0
이 Column을 추가했을 때를 봅시다. titanic_df['Age_0'] = 0 이라는 코드를 통해 컬럼을 새롭게 생성했네요. 이전에
DataFrame[컬럼명]을 통해 해당 컬럼의 Series에 접근할 수 있다는 것을 배우셨을 겁니다. 이러한 방법을 통해 새 컬럼을 추가했다고 생각하면 되겠네요. 만약 상수값을 할당하면 해당 Column의 데이터는 모두 0으로 초기화된다는 것 알아둡시다!
2) Age_by_10
이 Column을 추가할 때의 코드를 봅시다. titanic_df['Age']라는 Series와, 10이라는 상수를 곱한 것으로 보이네요. 이처럼 상수를 곱하면 해당 Series의 모든 데이터에 일괄적으로 상수가 곱해집니다. 덧셈 또는 뺄셈 또는 나눗셈도 마찬가지겠죠!
3) Family_No
이 Column을 추가할 때의 코드를 봅시다. titanic_df['SibSp']와 titanic_df['Parch']를 덧셈으로 연산하는 부분이 보이네요. 이전에 2)에서 처럼 상수를 더하고 곱할 수 있듯이, Series끼리 서로 더하거나 곱하는 등의 연산이 가능합니다!
[2] DataFrame의 데이터를 삭제하자!
DataFrame의 데이터를 어떻게 삭제할지에 대해 먼저 알아봅시다.
바로, DataFrame.drop(labels = None, axis = 0, index = None, columns = None, level = None, inplace = False, errors = 'raise')라는 메소드를 사용합니다.
가장 중요한 parameter는 labels와 axis, 그리고 inplace에요!
1) axis
parameter인 axis에 대해 먼저 알아봅시다. 이전에 제가 "행과 열이라는 표현보다는, axis0과 axis1이라는 표현이 더 정확하다"라고 말씀드린 적이 있는데요, 그 이유는 실제 pandas 등과 같은 데이터분석 라이브러리들은 axis라는 표현을 많이 사용하기 때문입니다! axis0은 행 방향(행이 증가하는 방향), axis1은 열 방향(열이 증가하는 방향)으로 알고 갑시다.
2) labels
저희가 실제 삭제하려하는 부분을 명시해주는 곳이라고 생각하면 편합니다. 하지만 labels에 들어갈 parameter는 axis가 무엇이느냐에 따라 달라져요!
만약 axis=0 이라면, labels에는 인덱스 번호를 적어줘야합니다. 그 이유는, axis=0이기에 컴퓨터는 행 방향으로 탐색을 시작해요. 행 방향으로 탐색을 하면서 입력한 인덱스 번호와 일치하는 행을 삭제합니다.
만약 axis=1 이라면, labels에는 컬럼의 이름을 적어줘야합니다. axis=1이기에 컴퓨터는 '열 방향으로 탐색을 시작해야겠다'라고 생각하고, 열 방향으로 탐색하면서 입력한 컬럼의 이름과 일치하는 열을 삭제합니다.
이해가 잘 안되신다면 잠시 후 나올 코드를 보면서 이해해봅시다!
3) inplace
inplace에는 True 또는 False를 할당해주어야 하며, 기본 값은 False입니다!
만약 inplace = False일 경우, 메소드를 사용한 DataFrame에서 데이터를 삭제한 후, 수정된 DataFrame을 return합니다!
만약 inplace = True일 경우, 메소드를 사용한 DataFrame 자체에서 데이터를 삭제해요. 원본이 변경되는거죠! 그리고, None을 return합니다. (어떤 것을 return할 필요가 없으니깐요ㅎㅎ)
이제 실제 코드를 확인해볼게요. 참고로 원래의 DataFrame은 아래 사진과 같습니다!

#Column 삭제
titanic_df_remove_Id = titanic_df.drop(labels=['PassengerId', 'Name', 'Ticket'], axis=1, inplace=False)
titanic_df_remove_Id.head()
PassnegerId, Name, Ticket Column이 삭제된 것을 확인할 수 있습니다! (여러 컬럼 데이터를 삭제하고 싶다면, 위 코드와 같이 list형태로 전달해주면 됩니다.)
axis=1이므로 컴퓨터는 열 방향으로 해당 컬럼을 탐색하다, 찾았으니 삭제한거죠!
inplace=False이므로 원본 DataFrame은 변경되지 않았겠죠?
#row 삭제
titanic_df_remove_2 = titanic_df.drop(labels=[0, 1, 2], axis=0, inplace=False)
titanic_df_remove_2.head()
0, 1, 2번째 인덱스에 해당하는 행이 삭제된 것을 확인할 수 있습니다!
여러 행을 삭제하고 싶다면, 해당하는 인덱스를 list형태로 전달하면 됩니다.
axis=0이므로 컴퓨터는 행 방향으로 입력한 인덱스를 찾다가, 찾았으니 해당하는 행을 삭제한 것입니다!
이 경우에도 inplace=False이므로 원본 DataFrame은 변경되지 않습니다!
정리)
ㆍaxis : DataFrame의 row를 삭제할 때는 axis=0, Column을 삭제할 때는 axis=1로 설정. 설정한 axis에 따라 labels를 자 동으로 인식한다!
ㆍ원본 DataFrame은 유지하고 드롭된 DataFrame을 새롭게 객체 변수로 받고 싶다면 inplace=False로 설정(디폴트 값임)
ㆍ원본 DataFrame에 드롭된 결과를 적용하고 싶을 땐 inplace = True. 단 리턴값이 None이다!!!
ㆍ원본 DataFrame에서 드롭된 DataFrame을 다시 원본DataFrame 객체 변수로 할당하면, 원본 DataFrame에서 드롭된 결과를 적용할 경우와 같음.
즉, titanic_df = titanic_df.drop('Age_0', axis=1, inplace=False)는 titanic_df.drop('Age_0', axis=1, inplace=True)와 같다!
[3] Index 객체에 대해 알아보자!
# 원본 데이터 다시 로딩
titanic_df = pd.read_csv("C:/Users/82102/Desktop/sw/PythonMLGuide/pandas/titanic_train.csv")
# Index 객체 추출
indexes = titanic_df.index
print(indexes)
# Index 객체를 실제 값 ndarray로 변환
print('Index 객체 ndarray 값 : \n', indexes.values)RangeIndex(start=0, stop=891, step=1)
Index 객체 ndarray 값 :
[ 0 1 2 3 4 5 6 ... 889 890]Index에 대해 알아봅시다!
DataFrame이던 Series던 각 행을 구분하기 위한 Index가 있었다는 것 기억하시죠? 이에 대해 접근하는 것입니다.
Index객체 추출은 DataFrame.index를 통해 할 수 있습니다. DataFrame.index를 print해보면 Index의 범위와 step 등이 나오네요! 실제 값에 접근해볼까요? DataFrame.index.values를 통해 실제 값에 접근할 수 있어요! 참고로, 이 배열은 ndarray형입니다.
print(type(indexes.values))
print(indexes.values.shape)
print(indexes[:5].values)
print(indexes.values[:5])
print(indexes[6])<class 'numpy.ndarray'>
(891,)
[0 1 2 3 4]
[0 1 2 3 4]
6위와 같은 방법으로 단일 값 접근 인덱싱 및 슬라이싱을 할 수 있다는 것도 알아둡시다!
주의해야할 점은, 한 번 만들어진 DataFrame 및 Series의 Index 객체는 함부로 변경할 수 없어요. 즉, 다음과 같은 작업은 할 수 없다는 것이죠.
indexes[0] = 5
Series객체를 출력했을 때의 결과를 기억하시나요? DataFrame에서 특정 컬럼에 접근하여 Series객체에 접근 했을 때를 생각해봅시다. 자동으로 Index가 포함되어있었죠? 이 처럼, Series 객체 역시 DataFrame과 마찬가지로 Index 객체를 포함하지만 연산 시에는 Index는 자동으로 제외됩니다. 즉, Index는 식별용으로만 사용된다는 것이죠! 아래 코드를 봅시다.
Series_fair = titanic_df['Fare']
print("titanic_df['Fare'].max() : ", Series_fair.max())
print("titanic_df['Fare'].min() : ", Series_fair.min())
print("sum(titanic_df['Fare']) : ", sum(Series_fair))
print("titanic_df['Fare'] + 3 : \n", (Series_fair + 3).head())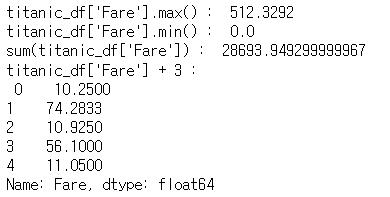
Series 연산 시 Index는 자동으로 제외되네요~ 만약 Index도 연산되었으면 결과값이 두개씩 나왔겠죠?
titanic_reset_df = titanic_df.reset_index(inplace = False)
titanic_reset_df.head()
DataFrame.reset_index()를 통해 새로운 인덱스를 생성할 수 있어요. 이게 언제 필요한지 생각해봅시다.
데이터 전처리를 하는 과정에서 행을 삭제하는 경우가 굉장히 많아요. 그렇게 되면 Index가 연속적인 숫자열이 아니겠죠? 이를 보완하기 위해 DataFrame.reset_index()를 사용합니다! 새롭게 인덱스를 연속 숫자형으로 할당하는거죠.
이 때, 기존 Index는 'index'라는 새로운 칼럼명으로 추가됩니다.
주의해야할 점이 있어요. DataFrame['Column'] 등으로 특정 Series를 추출해봤다고 합시다. 이 Series에서 reset_index()를 적용하면 반환형은 Series가 아닌 DataFrame입니다. 그 이유는 Series란 '하나의 컬럼과 인덱스'로 이루어진 것을 말하는데, 기존 Index가 'index'라는 이름의 새로운 컬럼으로 추가되기에 컬럼이 총 2개가 되는 것이죠. 따라서 DataFrame이 반환됩니다.
reset_index()메소드엔 두 가지 parameter를 입력할 수 있어요. 첫 번째는 inplace, 두 번째는 drop 입니다.
ㆍinplace : 이전에 drop메소드에서의 inplace를 기억하시나요? 이와 완전히 같은 역할입니다! 기본값은 False입니다.
ㆍdrop : 이 parameter를 True로 설정한다면, 기존 인덱스는 'index'라는 새로운 컬럼으로 추가되는 것이 아니고 바로 삭 제됩니다. 만약, Series.reset_index()를 사용할 때 drop = True로 설정한다면, 반환형은 DataFrame이 아닌 Series겠죠? 컬럼이 여전히 1개일 것이니까요!
value_counts = titanic_df['Pclass'].value_counts()
print("titanic_df['Pclass'].value_counts() : \n", value_counts)
print("Type of titanic_df['Pclass'].value_counts() : ", type(value_counts))
print('\n')
value_counts_new = value_counts.reset_index()
print("titanic_df['Pclass'].value_counts().reset_index() : \n", value_counts_new)
print("Type of titanic_df['Pclass'].value_counts().reset_index() : ", type(value_counts_new))titanic_df['Pclass'].value_counts() :
3 491
1 216
2 184
Name: Pclass, dtype: int64
Type of titanic_df['Pclass'].value_counts() : <class 'pandas.core.series.Series'>
titanic_df['Pclass'].value_counts().reset_index() :
index Pclass
0 3 491
1 1 216
2 2 184
Type of titanic_df['Pclass'].value_counts().reset_index() : <class 'pandas.core.frame.DataFrame'>앞 에서 다루었던 Series.value_counts()를 이용한 예시입니다.
3, 1, 2는 하나의 index라고 말씀드렸죠? 하지만, value_counts()는 '해당 데이터를 가지고 있는 행이 몇개인가?'를 반환하기 3, 1, 2는 실제 어떠한 '의미'가 있는 값이죠. 즉, 단순 구분을 위한 '인덱스'로 두기엔 아깝다는 말입니다.
이 때, reset_index를 사용하여 새로운 index를 부여할 수 있겠죠? 또한, 이 때 DataFrame이 반환된다는 것 잊지맙시다!
[4]-1 데이터 셀렉션 및 필터링을 위한 '[ ]'
넘파이의 경우 '[ ]' 연산자 내 단일 값 추출, 슬라이싱, 팬시 인덱싱, 불린 인덱싱을 통해 데이터를 추출했었습니다!
판다스의 경우, ix[ ], iloc[ ], loc[ ] 등을 통해 동일한 작업을 수행하는데요, 그 전에 판다스의 '[ ]'연산자를 먼저 알아보도록 합시다.
import pandas as pd
titanic_df = pd.read_csv("C:/Users/82102/Desktop/sw/PythonMLGuide/pandas/titanic_train.csv")
print("단일 컬럼 데이터 추출 \n", titanic_df['Pclass'].head(3)) # Series
print("\n 여러 칼럼의 데이터 추출 \n", titanic_df[['Survived', 'Pclass']].head(3)) # DataFrame
print(type(titanic_df[['Survived', 'Pclass']]))
print("[]안에 숫자 index는 KeyError 발생\n", titanic_df[0])단일 컬럼 데이터 추출
0 3
1 1
2 3
Name: Pclass, dtype: int64
여러 칼럼의 데이터 추출
Survived Pclass
0 0 3
1 1 1
2 1 3
<class 'pandas.core.frame.DataFrame'>
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)기본적으로, 앞에서 다루었듯이 판다스 라이브러리 같은 경우 '[ ]'내에 컬럼명이 들어갔었죠? 넘파이 라이브러리의 경우 행, 열 등이 들어갈 수 있었지만 판다스의 경우 '[ ]'내에 컬럼명이 들어간다고 생각합시다.
또한, 여러 Column을 추출하고 싶을 경우 list를 활용하면 돼요! 이 경우 Column이 여러개이기 때문에 반환형은 DataFrame이겠죠!
판다스의 경우 '[ ]'내에 숫자를 함부로 입력하면 안됩니다. 숫자가 들어갈 수는 있지만 '인덱스 형식의 형태로 변환 가능한 표현식'이어야만 합니다. 위 예시 코드를 보시죠. titanic_df[0]은 에러인 것을 확인할 수 있습니다. 0이라는 index로 인식을 왜 못하냐고요? 판다스는 [ ]내에 있는 값을 Column이라고 먼저 인식하기에, 0이라는 Column은 없어서 오류가 발생한다고 이해하면 됩니다. 하지만 '인덱스 형식의 형태로 명확히 인식 가능한' 숫자형은 가능합니다. 아래 코드를 봅시다!
titanic_df[0:2]
[0:2]와 처럼 슬라이싱 값을 '[ ]' 내에 집어넣었죠. 이 경우 'Column이 아니라는 것을 명확히 인식'하게 됩니다. 따라서, index값으로 데이터를 추출할 수 있는 것이죠. 또한, 인덱스가 숫자가 아닌 'one', 'two' 등의 임의의 문자열일 경우에도 사용할 수 있습니다. 하지만 이런 접근 방법은 지양합시다.
또헌 불린 인덱싱 표현도 가능합니다. 조건을 만족하는 데이터를 추출하기 위해 매우 많이 사용되므로 꼭 알아둡시다!
아래 코드는 Pclass 컬럼 값이 3인 데이터 3개만 추출합니다.
titanic_df[titanic_df['Pclass'] == 3].head(3)
정리)
ㆍDataFrame 바로 뒤의 [ ]연산자는 넘파이의 [ ]나 시리즈의 [ ]와 다릅니다.
ㆍDataFrame 바로 뒤의 [ ] 내 입력 값은 Column명(또는 Column 리스트)를 지정해 컬럼 지정 연산에 사용하거나 불린 인덱스 용도로만 사용해야 합니다.
ㆍDataFrame[0:2]와 같은 슬라이싱 연산으로 데이터를 추출하는 방법은 사용하지 않는게 좋습니다.
[4]-2 데이터 셀렉션 및 필터링을 위한 ix[ ]연산자
넘파의 ndarray의 [ ]와 유사한 기능을 제공하기 위해 판다스는 ix[ ]연산자를 개발하였습니다!
ix[0, 'Pclass']와 같이 행 위치 지정으로 인덱스 값 0, 열 위치 지정으로 컬럼 명인 'Pclass'를 입력해 원하는 위치의 데이터를 추출할 수 있었습니다! 즉, ix[ ]의 행에 해당하는 위치 지정은 DataFrame의 인덱스 값으로 지정합니다. 독특하게 ix[ ]의 열에 해당하는 위치 지정은 Column의 이름으로 할 수도, 그리고 ix[0, 2]와 같이 컬럼 명이 아닌 컬럼의 위치 값 지정으로도 가능합니다.
전자와 같은 ix[ ]연산자의 처리 방식은 컬럼 명칭(label) 기반 인덱싱이며, 후자의 경우는 칼럼 위치(position) 기반 인덱싱이라고 칭합니다. 하지만, 이러한 처리 방식이 코드의 가독성을 떨어뜨린다고 판단되어 ix연산자는 없어질 예정이라고 합니다. (Jupyter Notebook에서 ix연산자 사용 시 Error가 발생하네요. 이미 없어졌을지도 모르겠습니다.)
ix[ ]연산자를 대신할 컬럼 명칭 기반 인덱싱인 loc[ ]와 컬럼 위치 기반 인덱싱인 iloc[ ]이 새롭게 만들어졌으니 이에 대해 자세히 알아보도록 합시다!
[4]-3 데이터 셀렉션 및 필터링을 위한 iloc[ ]연산자
이를 다루기 전, iloc[ ]과 loc[ ]의 차이를 구분하기 위해 용어 정리를 먼저 해보겠습니다.
명칭(label)기반 인덱싱은 컬럼의 명칭을 기반으로 위치를 지정하는 방식입니다. 즉, '컬럼의 이름'으로 접근하는 것이죠!
위치(position)기반 인덱싱은 0을 출발점으로 하는 가로축, 세로축 좌표 기반의 행과 열 위치를 기반으로 데이터를 지정합니다. 따라서, 행 열 값에 정수가 입력됩니다.
이제 loc[ ]을 알아보기 위해 아래와 같은 두 개의 DataFrame을 사용하도록 하겠습니다. data_df_reset은 data_df에 reset_index를 적용시키고, index 컬럼의 이름을 바꾼 후, 인덱스 + 1을 한 DataFrame입니다.
data = {'Name' : ['Chulmin', 'Eunkyung', 'Jinwoong', 'Soobeom'],
'Year' : [2011, 2016, 2015, 2015],
'Gender' : ['Male', 'Female', 'Male', 'Male']}
data_df = pd.DataFrame(data, index = ['one', 'two', 'three', 'four'])
data_df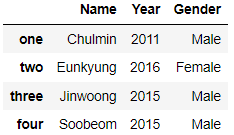
data_df_reset = data_df.reset_index()
data_df_reset = data_df_reset.rename(columns = {'index' : 'old index'})
data_df_reset.index = data_df_reset.index + 1
data_df_reset
data_df.iloc[0, 0]'Chulmin'DataFrame.iloc[ ]은 위치 기반 인덱싱입니다. 행과 열 ㄱ밧으로 interger 또는 interger형의 슬라이싱, 팬시 리스트 ㄱ밧을 입력해줘야 합니다. 즉, 0부터 시작하는 행과 열의 위치(정수)를 입력해주어야 하는 것이죠! 따라서, 위 코드는 data_df의 0번째 행, 0번째 열의 데이터에 접근한 것을 알 수 있습니다.
아래 코드는 Error가 발생하는 코드입니다.
data_df.iloc[0, 'Name']
data_df.iloc['one', 0]iloc[ ]은 위치 기반 인덱싱인데, 인덱스의 명칭 또는 컬럼의 명칭을 입력했기 때문이죠!
data_df_reset.iloc[0, 1]'Chulmin'iloc[ ]은 다시 강조하지만, '위치' 기반 인덱싱입니다. 위 코드를 보면 행 위치에 0을 입력했죠? 따라서 저 0은 인덱스 0이 아닌, 0으로부터 시작하는 '위치 0'입니다. 그렇기에 인덱스에 0이 없는데도 정상적으로 데이터에 접근할 수 있었던 것이죠!
참고)
iloc[ ]은 슬라이싱과 팬시 인덱싱은 제공하나, '위치' 기반 인덱싱이라는 제약으로 인해 불린 인덱싱은 제공하지 않습니다.
[4]-4 데이터 셀렉션 및 필터링을 위한 loc[ ]연산자
print("data_df.loc['one', 'Name'] : ", data_df.loc['one', 'Name'])
print("data_df_reset.loc[1, 'Name'] : ", data_df.loc['one', 'Name'])data_df.loc['one', 'Name'] : Chulmin
data_df_reset.loc[1, 'Name'] : Chulminloc[ ]연산자는 '명칭' 기반 인덱싱입니다. 이 때, '인덱스'는 항상 정수형일 것이라는 선입견을 가지면 안됩니다. 문자열일 수도 있어요!즉, 행의 자리에는 '인덱스'를, 열의 자리에는 '컬럼명'을 써주어야 하는 것이죠. (열 방향의 이름은 컬럼 명, 행 방향의 이름은 인덱스라고 생각할 수 있습니다.)
따라서, 다음과 같은 코드는 오류가 발생합니다.
data_df_reset.loc[0, 'Name']---------------------------------------------------------------------------
ValueError Traceback (most recent call last)data_df_reset의 인덱스엔 0이란 값이 없기 때문이죠! 이에 굉장히 유의해야 합니다.
print("data_df.iloc[0:1, 0] : \n", data_df.iloc[0:1, 0])
print('\n')
print("data_df.loc['one':'two', 0] : \n", data_df.loc['one':'two', 'Name'])data_df.iloc[0:1, 0] :
one Chulmin
Name: Name, dtype: object
data_df.loc['one':'two', 0] :
one Chulmin
two Eunkyung
Name: Name, dtype: object위는 iloc과 loc에 슬라이싱을 적용한 코드입니다.
loc에 슬라이싱을 적용할 때엔 굉장히 주의해야합니다. 일반적으로 슬라이싱 start : end를 한다면, start ~ end-1 까지를 의미하죠? 하지만 loc는 그렇지 않습니다. '명칭'기반 인덱싱이라는 특성으로 인해 -1 을 할 수 없는 경우까지 생각해주어야 하기 때문입니다. 따라서, loc에 슬라이싱을 적용할 때엔 start ~ end라는 것을 꼭 기억해야합니다! 아래 예시를 보고 차이점을 파악해주세요. 행 자리에 슬라이싱으로 정수가 들어가더라도 loc이기에 end까지 포함합니다!
data_df_reset.loc[1:2, 'Name']1 Chulmin
2 Eunkyung
Name: Name, dtype: object
주의해야할 점이 또 있습니다. 하나의 데이터에 접근할땐 return형이 str 또는 integer 등입니다. 하지만, 슬라이싱을 통해 여러 데이터에 접근할 때는 return형이 Series 또는 DataFrame입니다. 컬럼이 들어갈 자리에 하나의 컬럼만을 입력하면 Series를, 복수의 컬럼이 슬라이싱 등을 통해 입력될 때는 DataFrame이 반환되겠죠?
정리)
ㆍ명칭 기반 인덱싱과 위치 기반 인덱싱의 차이를 이해하는 것이 중요합니다. DataFrame의 인덱스나 칼럼명으로 데이터에 접근하는 것은 명칭 기반 인덱싱입니다. 0부터 싲가하는 행, 열의 위치 좌표에만 의존하는 것이 위치 기반 인덱싱입니다.
ㆍiloc[ ]는 위치 기반 인덱싱만 가능합니다. 따라서 행과 열 위치 값으로 정수형 값을 지정해 원하는 데이터를 반환합니다.
ㆍloc[ ]는 명칭 기반 인덱싱만 가능합니다. 따라서, 행 위치에 DataFrame의 인덱스가 오며(정수일수도, 문자열일수도 있습니다.) 열 위치에는 컬럼명을 지정해 원하는 데이터를 반환합니다.
ㆍ명칭 기반 인덱싱(loc[ ])에서 슬라이싱으로 start : end를 지정할 때, 시작점에서 종료점을 포함한 위치에 있는 데이터를 반환합니다.
ㆍ슬라이싱 등을 통해 복수의 데이터에 접근할 경우, 반환값은 Series 또는 DataFrame입니다. 단일 데이터에 접근할 경우 일반적으로 str, interger 등입니다.
[5] 매우 중요한 불린 인덱싱!!
불린 인덱싱은 굉장히 중요한 인덱싱 방법입니다. 수만개의 행이 있는 거대한 데이터 셋을 생각해봅시다.
어떠한 데이터에 접근하고 싶은데, 위치 기반 인덱싱이나 명칭 기반 인덱싱으로 접근하는 것은 굉장히 어렵겠죠? 값을 직접 입력해주어야 하니까요!
하지만, '내가 원하는 조건'을 통한 불린 인덱싱으로 데이터에 접근하는 것은 굉장히 효율적이며 간단합니다. 아래 코드를 통해 학습해봅시다!
import pandas as pd
titanic_df = pd.read_csv("C:/Users/82102/Desktop/sw/PythonMLGuide/pandas/titanic_train.csv")
titanic_boolean = titanic_df[titanic_df['Age'] > 60]
print("Type of titanic_df[titanic_df['Age'] > 60]", type(titanic_df[titanic_df['Age'] > 60]))
titanic_boolean.head()
numpy 라이브러리에서의 불리언 인덱싱을 기억하실 겁니다. 그와 아주 유사하죠? 위 처럼 간단한 코드를 통해 조건에 부합하는 데이터들을 추출할 수 있습니다. DataFrame에서 일부를 추출하고, Column이 여러개이므로 반환형은 당연히 DataFrame이겠죠!
따라서, 아래와 같이 추출한 DataFrame에 대해서 특정 Column만 추출하는 것도 가능합니다.
titanic_boolean[['Survived', 'Name']].head()
또한 여러개의 복합 조건을 결합해 사용할 수도 있습니다.
titanic_df[(titanic_df['Age'] > 60) & (titanic_df['Pclass'] == 1) & (titanic_df['Sex'] == 'female')]
ㆍand 조건 일 때는 &
ㆍor 조건 일 때는 |
ㆍNot 조건일 때는 ~
를 사용하면 됩니다! 여러 조건을 결합하는 것은 if문 등에서도 자주 사용되니 어렵지는 않죠?
cond1 = titanic_df['Age'] > 60
cond2 = titanic_df['Pclass'] == 1
cond3 = titanic_df['Sex'] == 'female'
titanic_df[cond1 & cond2 & cond3]
위와 같이 조건을 하나의 변수로 설정하여 복합 조건을 사용하는 것도 가능합니다!
조건이 많을 경우, 또는 중복돼서 자주 사용될 경우 위와 같은 방식이 코드의 가독성을 더욱 높여주겠네요.
- 본 글은 파이썬 머신러닝 완벽 가이드 (권철민 지음)을 공부하며 내용을 추가한 정리글입니다. 개인 공부를 위해 만들었으며, 만약 문제가 발생할 시 글을 비공개로 전환함을 알립니다.
'Artificial Intelligence > [파이썬 머신러닝 완벽가이드]' 카테고리의 다른 글
| [파이썬 머신러닝 완벽가이드] Chap02-2. 사이킷런 기반 프레임워크 익히기 (0) | 2022.01.06 |
|---|---|
| [파이썬 머신러닝 완벽가이드] Chap02-1. 사이킷런 - 붓꽃 품종 예측하기 (0) | 2022.01.02 |
| [파이썬 머신러닝 완벽가이드] Chap01-2. pandas 라이브러리 3 (0) | 2022.01.02 |
| [파이썬 머신러닝 완벽가이드] Chap01-2. pandas 라이브러리 1 (0) | 2021.12.30 |
| [파이썬 머신러닝 완벽가이드] Chap01-1. numpy 라이브러리 (0) | 2021.12.29 |


